
En el mundo actual, la cantidad de datos generados por empresas y usuarios aumenta exponencialmente, y con ella la necesidad de almacenar y procesar estos datos de manera efectiva. Es aquí donde entra en juego el concepto de Data Lake.
¿Qué es DATA LAKE?
Data Lake es un repositorio centralizado y escalable que permite almacenar grandes cantidades de datos estructurados, semiestructurados y no estructurados en su formato original. A diferencia de los almacenes de datos tradicionales, un Data Lake no requiere que los datos se transformen o se modelen de antemano, lo que lo hace más flexible y fácil de usar.
Beneficios
Entre los beneficios clave de un Data Lake se encuentran la capacidad de procesar grandes volúmenes de datos en tiempo real, la eliminación de la necesidad de migrar los datos a diferentes sistemas y formatos, y la posibilidad de analizar los datos de forma más rápida y eficiente.
Además, un Data Lake permite el acceso a una amplia gama de fuentes de datos, lo que puede mejorar la calidad y la variedad de los análisis realizados. También es escalable, lo que significa que se puede ampliar a medida que aumentan las necesidades de almacenamiento de datos.
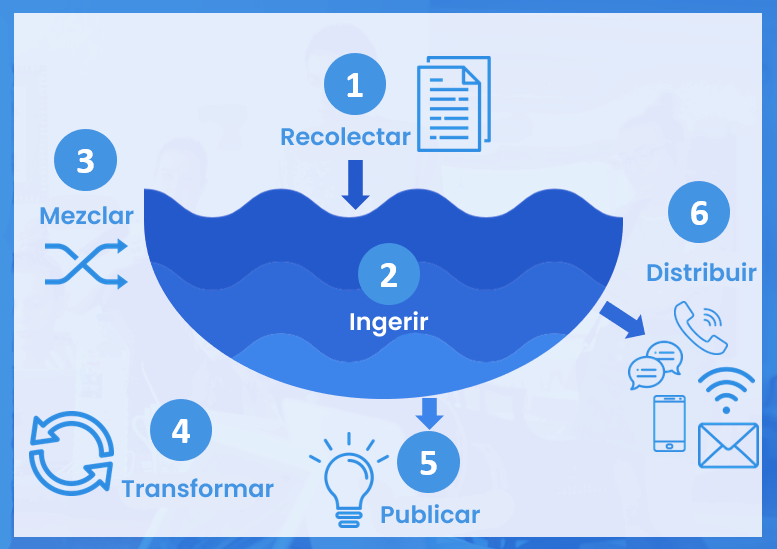
En términos de principios fundamentales, un Data Lake se basa en la idea de que todos los datos son valiosos y pueden ser útiles en algún momento, por lo que se deben almacenar de manera segura y accesible. También se enfoca en la agilidad y la flexibilidad, permitiendo a los usuarios trabajar con los datos de manera rápida y eficiente, sin tener que pasar por largos procesos de modelado de datos.
En conclusión, es una herramienta valiosa para cualquier empresa que maneje grandes cantidades de datos y busque mejorar la eficiencia y la calidad de sus análisis. Al seguir los principios fundamentales de agilidad, flexibilidad y valorización de todos los datos, un Data Lake puede ayudar a las empresas a mantenerse competitivas en el mercado actual.


